
A few years ago I built a couple of simple, event-driven data import pipelines using asynchronous APIs to automate some of my data import activities. I’m a big fan of serverless solutions and nanoservices like AWS Lambda or Google Cloud Functions (GCF). However, when using functions, you have to be aware of certain limitations and constraints. Such constraint is the timeout which is 9 minutes for GCF and 15 minutes for AWS Lambda at the time of writing this article.
Lets assume that we start a data import job with an asynchronous API from within a Cloud Function, and we have to wait for the import job to be completed. What if the processing time exceeds the timeout of the function?
One thing we can do is to split the logic into 2 parts. First we use a function to start the job (e.g. upload file), and then schedule another function to verify the progress later.
At the time of building that solution, several services existed on AWS for task scheduling. For example, an SQS message could be sent to a delay queue with an AWS Lambda function subscribed for receiving the message after the configured delay.
On Google Cloud Platorm (GCP) no delay queues existed at that time.
What did I use then? And how would I do it today? You will find the answers below.
The brief history of scheduler and task queue services on GCP
In 2008 Google announced Google App Engine (GAE) as a new developer tool that enables you to run your web applications on Google’s infrastructure without having to take care about the underlying resources. Over the years Google created various cloud services and bundled them with the App Engine.
If you needed an App Engine-bundled service like the App Engine Cron or Task Queues, then you needed to create an App Engine app even if you didn’t want to run your application on the App Engine.
In the meantime Google started unbundling these services from the App Engine into standalone service.
However some services are still – at least partly – bundled with the App Engine, for example the Cloud Scheduler – GCP’s task scheduler (cron) service, where an empty App Engine app needs to be created in the GCP project before you can use this service.
“Cloud Scheduler is currently available in all App Engine supported regions. To use Cloud Scheduler your Cloud project must contain an App Engine app that is located in one of the supported regions. If your project does not have an App Engine app, you must create one.”
Cloud Scheduler overview
It shouldn’t prevent you from using the Cloud Scheduler with your non-App Engine solutions, but you may run into difficulties like for example you won’t be able to change the region of your App Engine app once created, and you have to accept that various resources like e.g. service accounts, will be provisioned by Google for your App Engine app in your GCP project.
This is not the case with Cloud Tasks (was: Task Queues).
Cloud Tasks is a fully managed queue service with HTTP or GCP App Engine targets that lets you separate out pieces of work that can be performed asynchronously, outside of the main application flow.
Cloud Tasks doesn’t need an App Engine app in the GCP project any longer.
December 16, 2020
Cloud Tasks – release notes
“The relationship between your queues and your App Engine app has changed. If your queues only manage tasks with HTTP targets, you no longer need to have an enabled App Engine app.”
Use cases
With the Cloud Scheduler, various jobs can be scheduled using CRON scheduler expressions. It can be used for any job that needs to run in a certain schedule, for example:
- Automate infrastructure actions like starting or stopping compute instance VMs.
- Triggering batch workloads like data ingestion pipelines.
- Invoke App Engine targets or any HTTP endpoints on GCP or anywhere.
- Publish messages to Pub/Sub topics by a schedule.
I like the Cloud Scheduler for its reliable delivery and flexible retry policy.
On the other hand, Cloud Tasks is a fully managed queue service with HTTP or GCP App Engine targets that lets you separate out pieces of work that can be performed asynchronously, outside of the main application flow.
Cloud Tasks provides features like scheduling, task de-duplication, configurable retry policy, downstream rate limiting and retention of tasks up to 31 days.
Cloud Tasks does not provide strong guarantees around the timing of task delivery therefore it is not suitable to interactive application where the user is waiting for a result.
A possible use case where the task scheduling capability of Cloud Tasks is used can be observed on the following diagram.
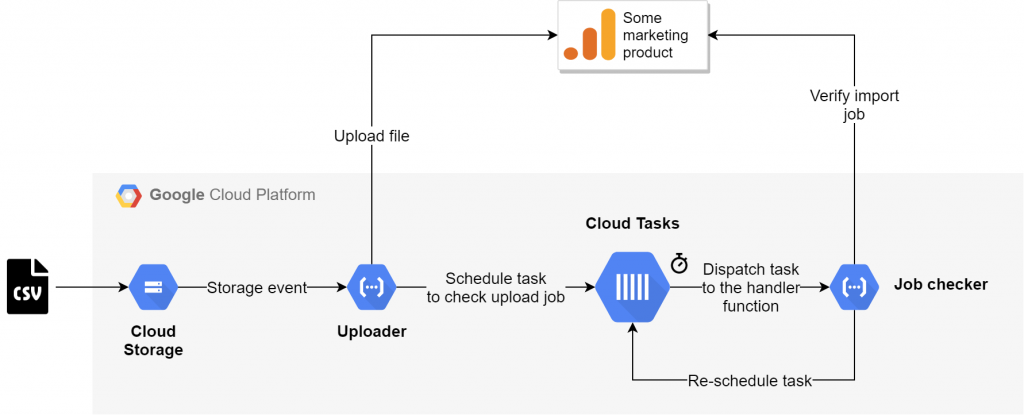
As seen on the diagram, a Cloud Function could initiate an asynchronous operation and schedule another function to be invoked by Cloud Tasks once at a later time. Once a task is completed, it is removed from the queue.
Lets review these services from various perspectives in the following sections.
Task/job scheduling
Cloud Scheduler
Scheduling a job with the Cloud Scheduler needs specifying a cron expression using unix cron format and the time zone. The maximum frequency that can be scheduled is 1 minute. It is also possible to choose timezones that do not observe daylight saving time.
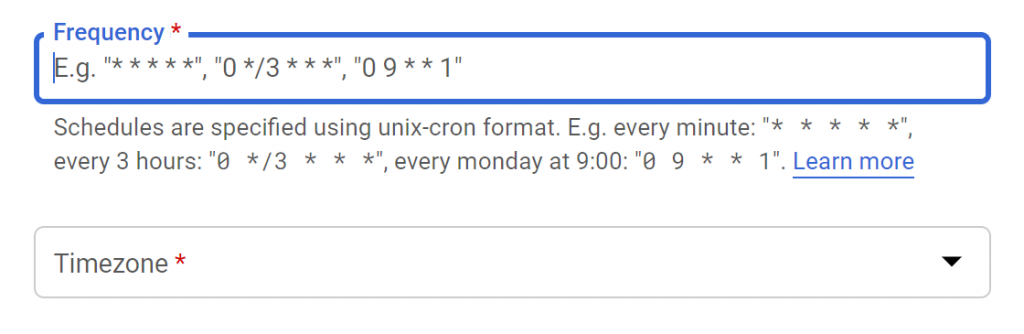
The service will keep executing the job until it is deleted. It is not possible to configure the job to run once or to end after N occurences. However the job can be deleted by the invoked target (e.g. HTTP Cloud Function) itself if needed.
Cloud Tasks
This article focuses on the scheduled tasks, therefore we won’t cover the case when the task needs to be dispatched immediately.
The scheduling feature of Cloud Tasks differs from a general scheduler service, because a task can be triggered by Cloud Tasks once at a specified time in the future. The schedule has to be set on task level using RFC3339 UTC format, so the tasks in the queue can have different schedules set if needed. The maximum schedule time for a task is 30 days from the current date and time. It is not possible to setup recurring tasks nor can we define a CRON based schedule. For that use case, check the Cloud Scheduler.
The only case when a task would be dispatched to the hander more than once is when the handler fails to consume the task and Cloud Tasks retries delivering the failed task.
Example for a valid schedule with the maximum (9) fractional digits:
2021-10-02T15:01:13.123456789ZA capability that I would like to see implemented by Google in the future is the ability to configure a schedule on queue level. For example, deliver each task 10 minutes after being added to the queue. Such capability exists on AWS already: SQS delay queue. A capability to use relative times like e.g. 5 minutes from now, would also be useful.
Endpoints (targets)
Cloud Scheduler
The supported targets of Cloud Scheduler jobs are
- HTTP endpoint
- App Engine target
- Pub/Sub
Cloud Tasks
- HTTP endpoint
- App Engine target
The approach with HTTP or App Engine targets is the same for Cloud Scheduler and Cloud Tasks.
For HTTP, the target can be any generic HTTP endpoint on GCP or elsewhere. To configure the target, the HTTP method, the URL and the body content have to be specified. HTTP headers can also be configured. Securing the target is also supported, this is covered later in this article.
Upon success, the handler must send a HTTP response code from the 2xx (success) range to the service, otherwise the service will invoke the handler again, according to the configured retry settings.
Cloud Scheduler supports an additional target: Pub/Sub, that Cloud Tasks doesn’t. To use that, a message body and a topic within the same project has to be selected.
Pub/Sub is integrated with many other GCP services, therefore Cloud Scheduler can be used as the scheduler for launching pipelines or any other user case where a Pub/Sub message is needed as the trigger.
Fault handling and retries
Both services provide a flexible retry approach with a backoff policy.
Cloud Scheduler
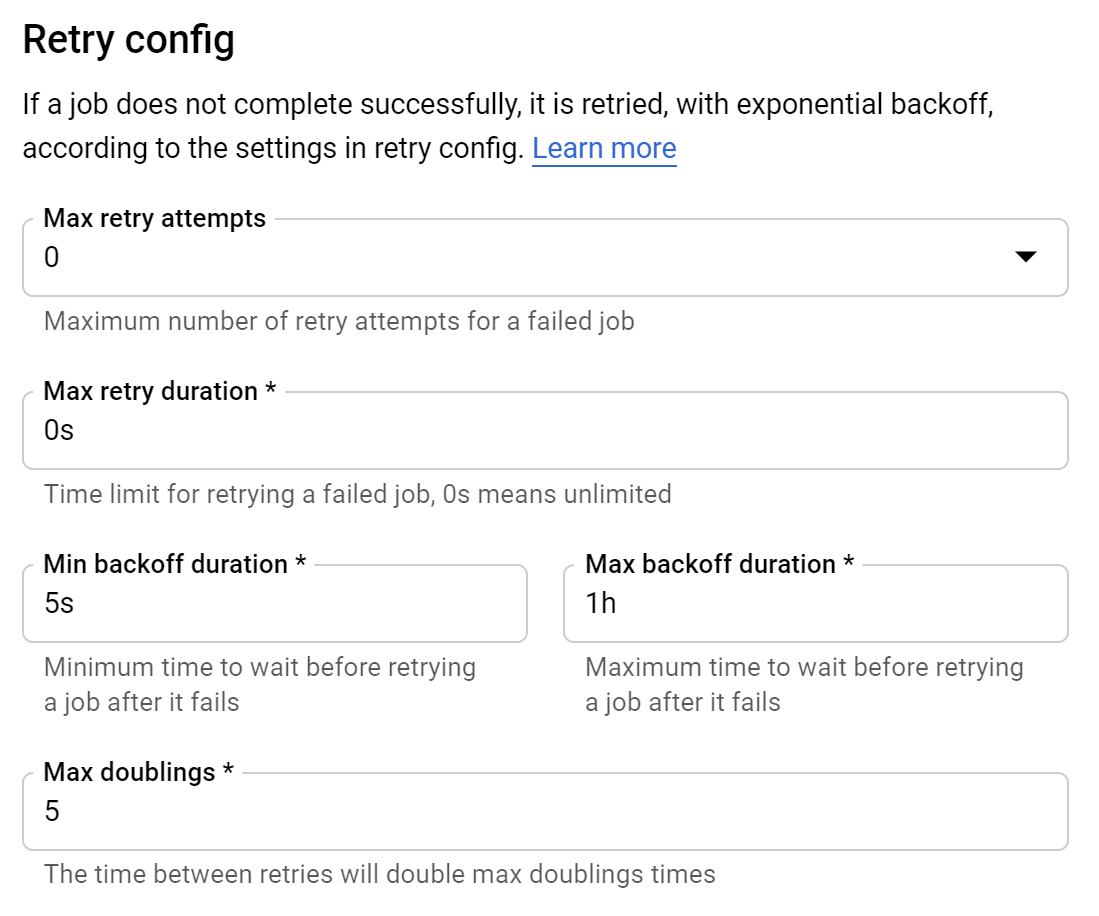
A job’s retry settings are configured when a job is created.
Cloud Tasks
The retry configuration for Cloud Tasks is set on queue level (not on the individual tasks) when the queue is created.

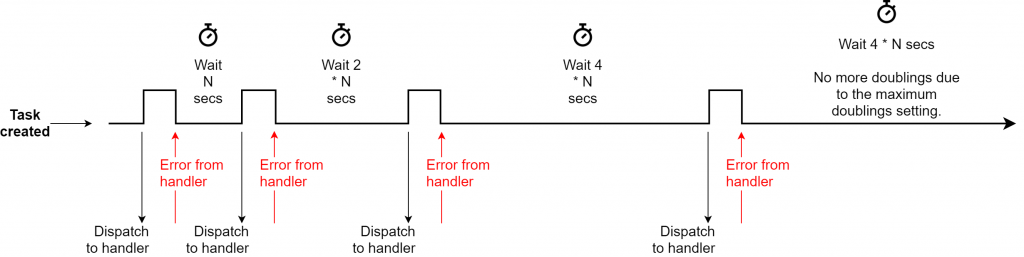
A handler can acknowledge a task by returning a success response. A task with an error response from the handler is retried.
Additionally, a dispatch deadline can be set for each task so Cloud Tasks can mark an attempt as failed and retries the task as per the retry configuration in case of handler timeout, too.
Security (authentication with HTTP targets)
To invoke a Google endpoint by a scheduler job or cloud task securely, you can use short lived service account credentials, that can be either an OIDC token or an OAuth token added by the Cloud Tasks or Scheduler services automatically. This is done on job/task (and not on queue) level.
To use OIDC token, the audience (usually the root URL of the handler) and the service account email has to be specified. For OAuth, the scope and the service account email are needed. The service account has to be a local one that is created in the same GCP project as the Cloud task or Scheduler job.
The endpoint can be in the same or in a different GCP project, assuming that the service account has been granted the necessary permissions to invoke the endpoint (e.g. Cloud Functions Invoker).
But how can Cloud Scheduler or Cloud Tasks get the token without providing credentials like e.g. a key file?
When you enable the Cloud Scheduler or Cloud Tasks APIs, Google generates a default service account for these services with the permission required to generate header tokens on behalf of your client service account to authenticate to the configured HTTP target.
HTTP target handler authentication with Cloud Tasks and Cloud Scheduler
Google’s recommendation is that OIDC tokens should generally be used for any handler running on Google Cloud, for example, a Cloud Function or Cloud Run service. Google APIs hosted on *.googleapis.com expect an OAuth token.
Reliability
Cloud Scheduler
Google says that the Cloud Scheduler is an enterprise-grade cron job scheduler. They guarantee at-least-once delivery to the configured job target. Those who work with cloud messaging solutions know that this is what the providers usually guarantee using the standard settings (AWS standard queues, SNS standard topics, etc.). There is no exactly once delivery option provided by Cloud Scheduler. The job target must be made idempotent to ensure that the message gets processed only once.
See Google’s pro tip for building idempotent functions.
Cloud Tasks
Ordering not guaranteed
No guarantees or best efforts are made by Google to execute tasks in any particular order. Exceptions are the scheduled tasks that will run at the time specified.
At-least once delivery
Similar to Cloud Scheduler jobs, “in situations where a trade-off must be made between guaranteed execution and duplicate execution, the Cloud Tasks service errs on the side of guaranteed execution, therefore duplicate execution may occur.” (Cloud Tasks – Common pitfalls)
To mitigate the risk it is a best practice to design idempotent handlers that can be executed several times with the same task without changing the final result.
Task de-duplication
Cloud Tasks offers a feature to help avoiding adding the same task twice on the producer side by maintaining a task de-duplication window. Adding a task with the same ID as an existing or recently deleted task will cause the service to reject it. The task ID is optional, but to use the de-duplication feature, the task ID has to be explicitly specified by the producer.
Task de-duplication remains in effect for ~1 hour after a task is deleted.
If you do not need task deduplication, do not specify task IDs explicitly when adding tasks to the queue.
Note, that this feature prevents task duplication on the producer side only. On the handler side at-least-once delivery is provided.
Quotas and limits
For Cloud Scheduler a limit of 500 API requests per minute applies at the time of writing this article. The number of jobs is limited in 1000 per project but in can be increased to 5000. The maximum job size is limited in 1 MB.
For Cloud Tasks queues the user can define the dispatch rate and the number of concurrent tasks that can be dispatched for a queue. The maximum queue dispatch rate (the rate at which tasks can be dispatched from a queue) is 500 tasks dispatched per second per queue and the maximum allowed value for the maximum number of concurrent tasks is 5,000. If you need to dispatch at higher rates or need more concurrent tasks then you can use multiple queues. The maximum size of a task that can be added to a queue is 1 MB.
Constraints
One constrant that I would highlight in relation with the Cloud Scheduler is that it is still not detacted from the App Engine completely. Using the Cloud Scheduler still requires an empty App Engine service to be created in the project even if your workload doesn’t require the App Engine. It can lead to difficulties, for example, you won’t be able to change the region of your App Engine app once created, and you have to accept that various resources like e.g. service accounts, will be provisioned by Google for your App Engine app in your GCP project automatically.
For Cloud Tasks I’ve found that a deleted queue cannot be re-created with the same project with the same name within 7 days after the deletion.
Pricing
Cloud Scheduler‘s pricing is based on the number of job definitions and not on job executions. It has a cost of $0.10 per job per month. If a job is deleted 1 day after created, then it costs $0.003.
3 jobs per month per billing account are free.
Cloud Tasks‘ billing is based on the number of operations. Billable operations are API calls and push delivery attempts. Creating a task and delivering to a target are at least 2 operations depending on the task size. Tasks are chunked at 32 KB for pricing purposes. The regular network costs are also added.
The cost is $0.40 per 1 million operations (up to 5 billion operations) but the first 1 million operations are free.
Summary
As discussed in the article, both services provide flexible, enterprise-grade solutions for task/job scheduling.
They have some common capabilities (e.g. target authentication, retry approach) and there are use cases where any of these services could be used, but each service has its own pros and cons.
From task/job scheduling perspective, Cloud Tasks is suitable for use cases where an operation has to be executed once at a specific time where the schedule – a specific date and time – is specified by the task’s publisher.
Cloud Scheduler is a better fit for scheduling recurring tasks using cron.
For the solution with the asynchronous API, discussed in the introduction, I created a Cloud Scheduler job after the import job was started. The scheduler then triggered a Cloud Function for checking the import job’s progress at a later time. I deleted the scheduler job on success, otherwise I let it run again based on the cron schedule a few times. In either case, the job had to be deleted by the handler.
Today I would use the Cloud Tasks service for the same task to schedule a function to run X minutes after an import job was started to check the job’s progress at a later time.
| Cloud Tasks | Cloud Scheduler | |
|---|---|---|
| Use case | – Separate out pieces of work – that can be done asynchronously – from your main workload to a worker. – Helping traffic spikes by removing non-user-facing tasks from the main user flow – Managing third-party API call rates – Executing tasks in the future at the scheduled delivery time | – Start/stop of compute instance VMs at a specific time of the day. – Launching scheduled pipelines. – Scheduling any workload that can be triggered via HTTP. |
| Endpoints (target) | – HTTP (on Google or elsewhere) – App Engine HTTP | – HTTP (on Google or elsewhere) – Pub/Sub – App Engine HTTP |
| Schedule | – Run once at a fixed time in the future. – Maximum schedule is 30 days. | – Recurring tasks scheduled using CRON like expressions. – One minute is the smallest interval supported. |
| Pricing | $0.40 per 1 million operations (up to 5 billion operations) + regular network costs | Billing is based on job definition: $0.10 per job per month ($0.003 per day) |
| Free quota | First 1 million operations, chunked at 32 kB, per month are free | 3 jobs per month are free per billing account |
| Task/job size | 1 MB | 1 MB (minus ~1 KB request overhead) |
| Throughput | – Max. 500 tasks dispatched per second per queue. – Max. 5000 concurrent tasks. | – Max. 500 API requests per minute. – Max. 5000 jobs per project. |
| Target authentication | – Auth header – OIDC or OAuth2 tokens added by the service – Custom authentication with HTTP headers | – Auth header – OIDC or OAuth2 tokens added by the service – Custom authentication with HTTP headers |
| Fault handling | Retry with backoff policy (min/max backoff duration, number of doublings, max attempts, max duration) | Retry with backoff policy (min/max backoff duration, number of doublings, max attempts, max duration) |
| Availability | 99.95% monthly uptime percentage | 99.95% monthly uptime percentage |
| Retention | 31 days task retention | Not applicable |