
I read a lot about GraphQL and found many aspects of it that I like. I thought that the best way to educate myself in this technology was to build a GraphQL API and a web application that uses the API. The idea is to consume content from Adobe Experience Manager (AEM) via GraphQL API.
GraphQL can be considered as a frontend directed technology for fetching or manipulating data in a more personalized manner that highly improves the developer experience and productivity in building and consuming APIs.
Many people like GraphQL because of its simplicity, its easy learning curve, the elegant programming style and increased development productivity that comes with GraphQL (and many others). It is a good fit for API-first projects.
This post is not supposed to be a GraphQL introduction. For that, I suggest reading the following quality posts. However, for the understanding of this post, a basic knowledge of GraphQL is useful.
OK, but why GraphQL, and why not REST?
There are some major differences between GraphQL and REST that one needs to understand before choosing one or the other.
- GraphQL can be considered as a query language, while REST is an architectural style. They can both be useful for API-first solutions, but GraphQL is a better fit and gives specific tools for building an API for the frontend while it can be tricky if someone wants to build a truly RESTful API.
- While in conventional REST we interact with a specific resource, GraphQL can interact with several resources to construct the dataset that the requester needs. In GraphQL you do not specify the identity of the resource(s) directly when you fetch it.
- GraphQL is more flexible in many ways, for example the consumer can specify what fields it needs in the response.
There is notable impact on (almost) every quality attribute when someone wants to move away from REST and introduce GraphQL: security, cacheability, maintainability, …
A great Medium article comparing the two technologies: GraphQL vs REST.
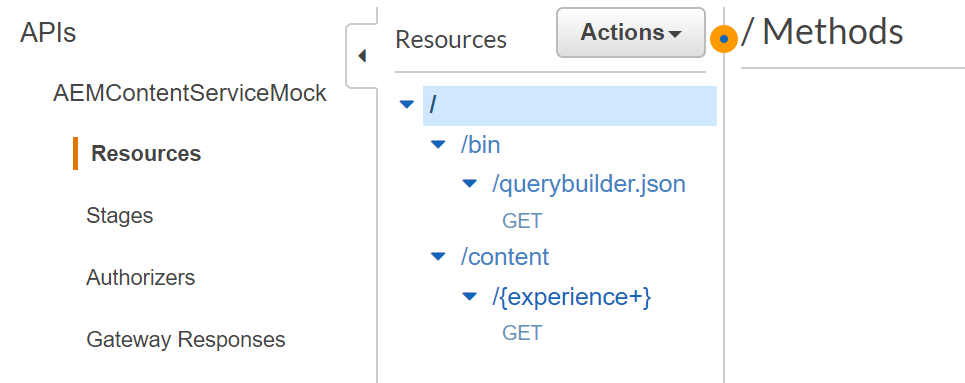
Fetching Content from AEM using GraphQL
The use case is the following. Articles are published in AEM by content authors but we want to display them on a React application that is built outside of AEM and needs to fetch the content via a GraphQL API. The demo application lists the available articles with pagination links on its home page. Clicking a link opens the article on full page.
The decision that I choose React for the frontend is unimportant. I choose it because of its popularity, but you could code the frontend in other popular frontend technologies.
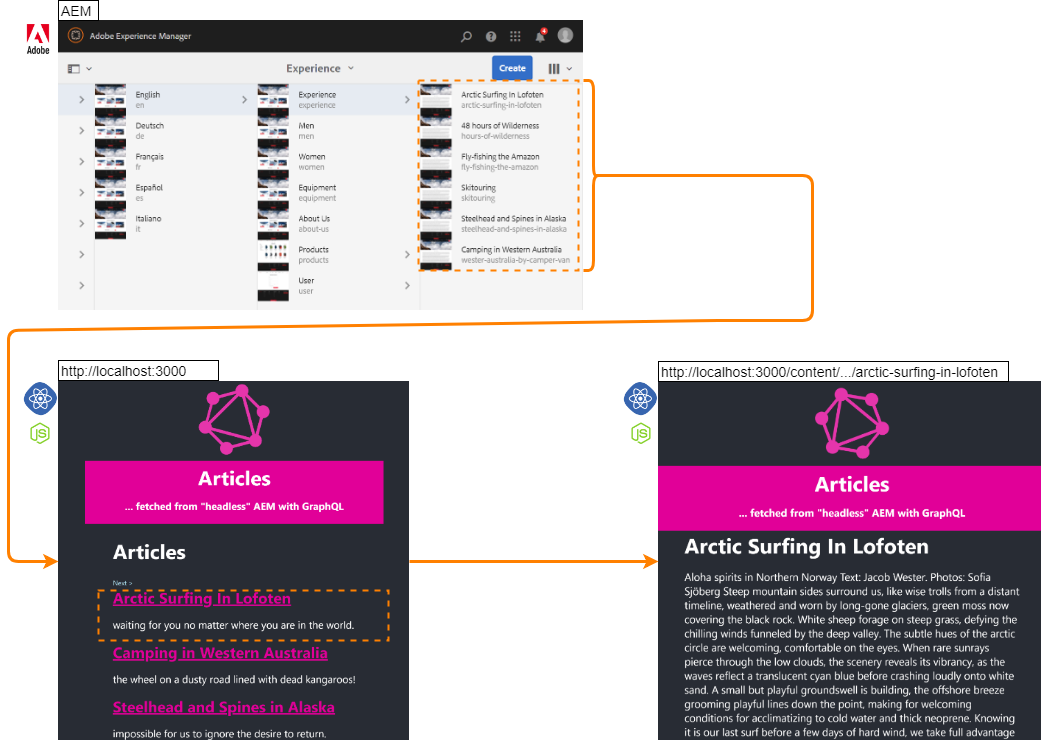
I considered several options to build the GraphQL API. To utilize the full power of GraphQL, I decided to build the API outside of AEM: on AWS. This setup has several benefits:
- AEM can be replaced with other CMS
- There can be additional downstream resources (not only AEM) involved into building the GraphQL response. Even in a query, one can combine data from multiple endpoints, DB, etc.
- When AEM is down, the GraphQL response can be constructed in other ways (from cache, Lambda function, …)
- A caching layer can be introduced between the GraphQL API and AEM
- AEM has several ways to get content out of it already. Lets use them rather than building an additional API layer which would put extra load on AEM.
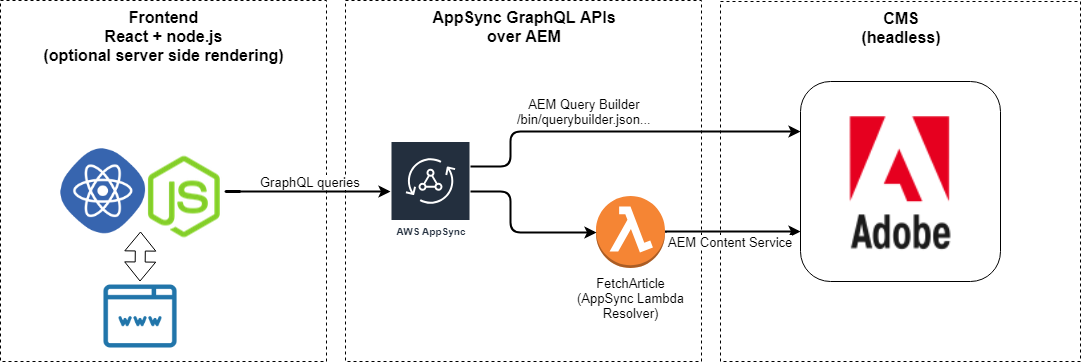
And this is where AWS Appsync comes in the picture (https://aws.amazon.com/appsync/).
“AWS AppSync makes it easy to build data driven mobile and web applications by handling securely all the application data management tasks like online and offline data access, data synchronization, and data manipulation across multiple data sources. AWS AppSync uses GraphQL, an API query language designed to build client applications by providing an intuitive and flexible syntax for describing their data requirement.”
High level solution overview:
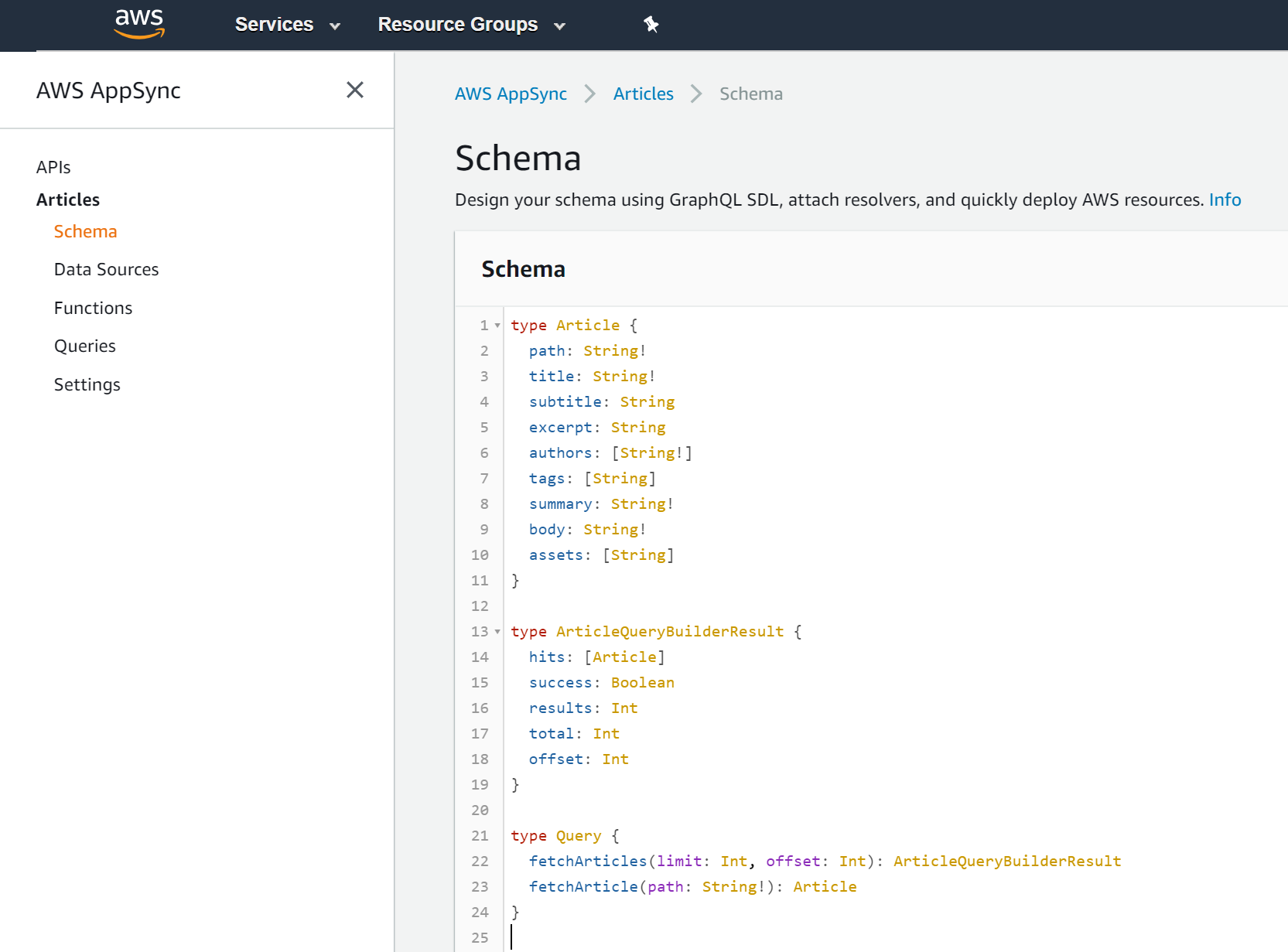
The GraphQL Schema
The most basic element of GraphQL is the Type, which represents an object.
The Article type is built from String fields (mandatory and optional ones) and String arrays:
type Article {
path: String!
title: String!
subtitle: String
excerpt: String
authors: [String!]
tags: [String]
summary: String!
body: String!
assets: [String]
}
For fetching the list of articles, we need another GraphQL type: ArticleQueryBuilderResult. It contains an array of Article objects and a few additional fields for building pagination on the frontend.
type ArticleQueryBuilderResult {
hits: [Article]
success: Boolean
results: Int
total: Int
offset: Int
}
Fetching the article list and a specific article goes by using GraphQL Queries:
- FetchArticles
- Retrieves the list of articles from AEM considering the specified offset and limit. Returns ArticleQueryBuilderResult.
- FetchArticle
- Retrieves a specific Article by its identifier (path)
type Query {
fetchArticles(limit: Int, offset: Int): ArticleQueryBuilderResult
fetchArticle(path: String!): Article
}
In this use case we do not create or alter content via GraphQL. For that, we would need to use Mutation rather than a Query, and we would need to create Input types that we can use as input parameters in the mutations.
Fetching Content from AEM
AEM provides a few ways out of the box to consume content via HTTP.
For FetchArticles, I use the AEM query builder API which can be used via HTTP. Using the query builder I search for pages of a specific resource type and retrieve their title, path, excerpt and additional arguments needed for supporting pagination links. Soon you will see that the query builder’s HTTP API can be integrated with AppSync quite easily, without having to write any complex code.
For FetchArticle, we can use the Sling Model Exporters that can be used to output a page in JSON.
I don’t have a publicly available AEM instance on the Internet, so I decided to mock the endpoints needed – on AWS. If you are interested in this part, scroll down to the end of this article.
Building the GraphQL API on AppSync
Open the AppSync console and choose “Build from scratch” (start from a blank API).
1. Schema
The first thing you need to do is to develop your sceham (types, queries, …).
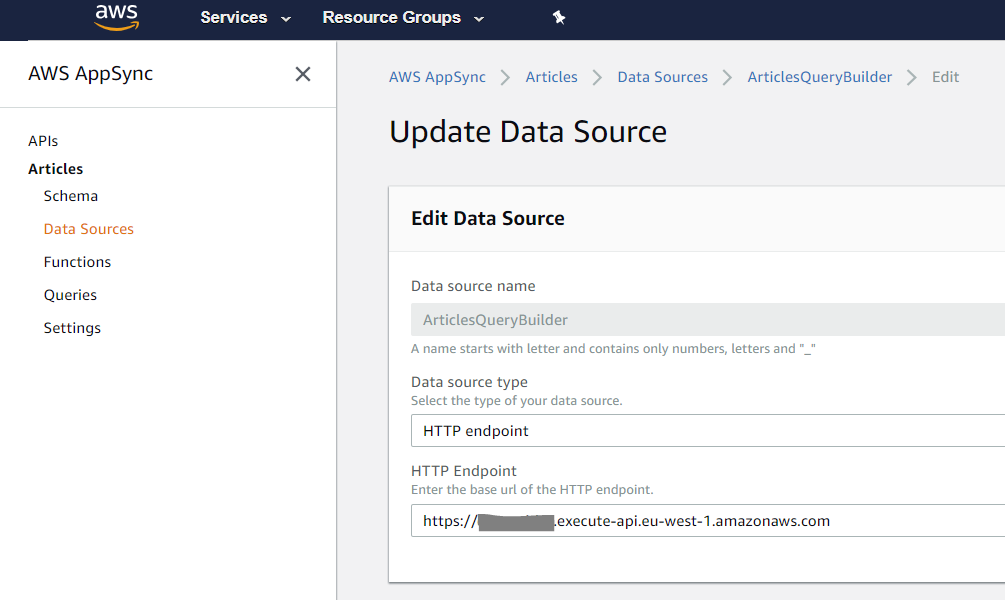
Next, we need to configure our AppSync data sources. In this prototype we will use 2 different AppSync data source types: a HTTP data source and an AWS Lambda data source.
2. Data Sources
ArticlesQueryBuilder: HTTP data source to access the AEM Query Builder
With this data source AppSync will issue a request to the AEM Query Builder. So configure this one as a HTTP data source and enter AEM’s (in my case the mock) base URL.
We will configure the mapping between the GraphQL query and the AEM Query Builder later.
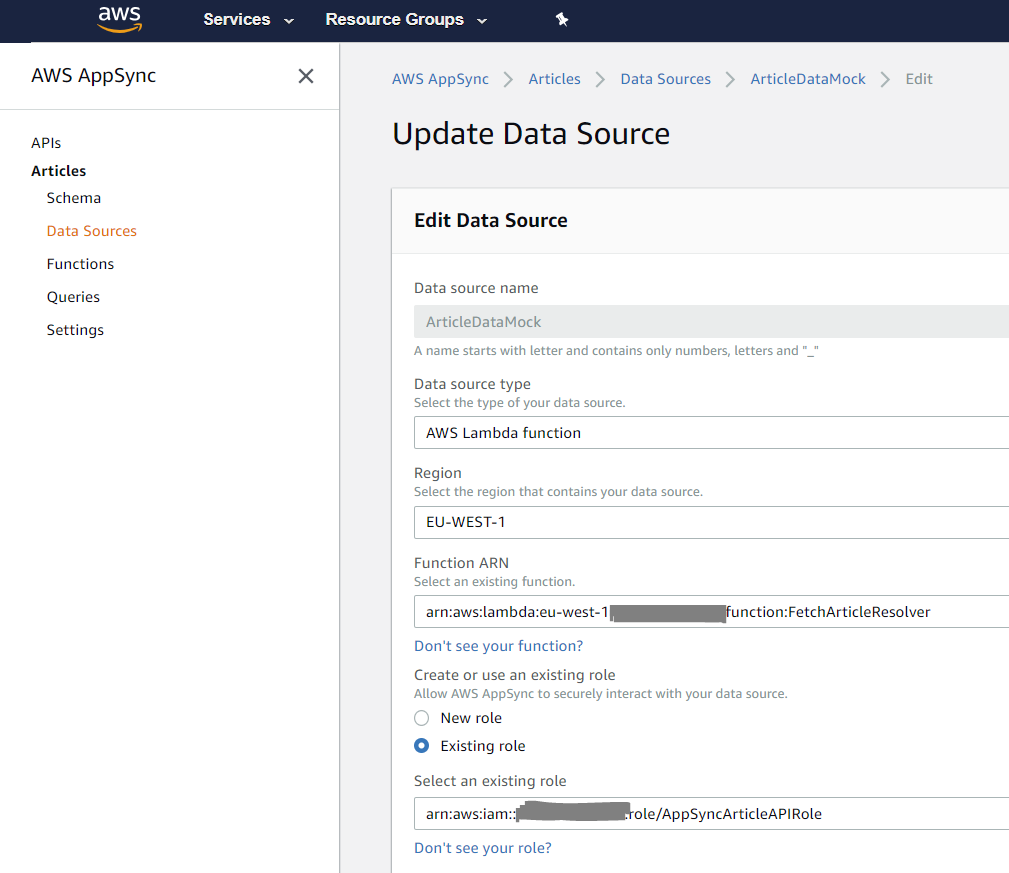
ArticleDataMock: AWS Lambda data source
Transforming the AEM page JSON to our GraphQL response needs some logic to be developed, therefore this data source needs to be configured as an AWS Lambda data source. Before this can be done, the serverless function has to be created on AWS Lambda.
Navigate to AWS Lambda and create a Lambda function: FetchArticleResolver (node.js 8.10)
const request = require('request');
const aemBaseUrl = 'https://XXXXXXXX.execute-api.eu-west-1.amazonaws.com/dev';
let jsonQueryResult = null;
exports.handler = function (event, context, callback) {
buildGraphqlResponseFromAEMContent(event.path, callback);
};
function getAttrFromResource(json, resType, attribute) {
const typeAttr = ":type";
if (json instanceof Object) {
if (resType == json[typeAttr]) {
jsonQueryResult = json[attribute];
} else {
for (let attr in json) {
getAttrFromResource(json[attr], resType, attribute);
}
}
} else if (json && resType == json[typeAttr]) {
jsonQueryResult = json[attribute];
}
return jsonQueryResult;
}
function getTitle(json) {
return json.title;
}
function buildGraphqlResponseFromAEMContent(path, callback) {
let articleUrl = aemBaseUrl + path + ".model.json";
request({ url: articleUrl }, (error, response, body) => {
console.log("error: ", error);
console.log("body: ", body);
let articleJSON = JSON.parse(body);
if (!error && articleJSON.title) {
let res = {
title: getTitle(articleJSON),
body: getAttrFromResource(articleJSON, "weretail/components/content/contentfragment", "text"),
assets: [getAttrFromResource(articleJSON, "weretail/components/content/heroimage", "src")]
}
callback(null, res);
} else {
console.log("error: " + error);
callback(error);
}
});
}
Return to AppSync and choose the previously created Lambda function for the data source you created.
Do not forget to create an IAM role that allows AppSync to invoke Lambda (inline policy below) and to push logs to CloudWatch Logs (AWS-managed policy: AWSAppSyncPushToCloudWatchLogs). These could be 2 separate roles, but I merged them into one.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "InvokePermission",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:eu-west-1:xxxxxxxx:function:FetchArticleResolver "
}
]
}
At the end you should have a data source configured similar to the following one:
3. Resolvers
Next we have to connect the queries to the data sources by developing request/response mapping templates. Mapping templates are written in a templating language called Apache Velocity Templating Language (VTL).
Go back to the Articles GraphQL Schema on AppSync and under Resolvers scroll to the Query part.
Resolver: fetchArticles
Click Attach next to fetchArticles.
Under Data source name, choose the previously created HTTP data source.
For help, visit the HTTP resolver mapping template reference.
For this prototype, the query arguments (offset, limit) are the same in my GraphQL query as the query string parameters needed for the AEM Query Builder, so we can just pass the arguments into the query in the request mapping template.
Similarly, we can just map the result into the GraphQL query result, because the majority of the fields is the same as the fields of the GraphQL type (title, path, excerpt, …) and we do not have to populate all fields.
Request mapping template:
{
"version": "2018-05-29",
"method": "GET",
"resourcePath": "/dev/bin/querybuilder.json",
"params":{
"query":$util.toJson($ctx.args),
"headers": {
"Authorization": "$ctx.request.headers.Authorization"
}
}
}
Response mapping template:
## Raise a GraphQL field error in case of a datasource invocation error
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
## If the response is not 200 then return an error. Else return the body **
#if($ctx.result.statusCode == 200)
$ctx.result.body
#else
$utils.appendError($ctx.result.body, $ctx.result.statusCode)
#end
Resolver: fetchArticle
Click Attach next to fetchArticle.
Under Data source name, choose the previously created AWS Lambda data source and setup the request/response templates the following was to invoke the Lambda function with the received arguments, and to use the result of the function as the GraphQL query result.
Request mapping template:
{
"version" : "2017-02-28",
"operation": "Invoke",
"payload": $util.toJson($context.arguments)
}
Response mapping template:
$util.toJson($context.result)
At this point, the GraphQL API is operational. You can test it on the AppSync console under Queries.
Sample queries:
query listArticlesQueryBuilder {
fetchArticles(offset: 0, limit: 3) {
hits {
path
title
excerpt
}
success
results
total
offset
}
}
query fetchArticle($path: String!) {
fetchArticle(path: $path) {
title
subtitle
body
authors
assets
}
}
For the fetchArticle() query, do not forget to set the path query variable to one of the paths supported by the Sling Model Exporters mock.
{
"path": "/content/we-retail/language-masters/en/experience/arctic-surfing-in-lofoten"
}
Troubleshooting
If your API doesn’t work, you may find the reason in the Cloudwatch logs. For this, you need to turn logging on under the Settings of the API. You need to create an IAM role that contains the AWS-managed AWSAppSyncPushToCloudWatchLogs policy.
Building the frontend
For building a frontend quickly I used Facebook’s Create React App “wizard” which can be used to bootstrap a React app in a few steps.
npm install -g create-react-app npx create-react-app articles npm i --save react-router-dom glamor react-apollo aws-appsync aws-appsync-react graphql-tag
The react-apollo module provides React integration for the Apollo client. I use aws-appsync to easily setup the connection to the AppSync GraphQL endpoint, and graphql-tag to support GraphQL query templates.
Some notable source snippets (please do not blame for ugly JS, I’m a backend guy 🙂 ):
Download your AppSync config from the Integrate with your app / Javascript section of the AppSync console and store in appsync_config.js. Then create you client with the following snippet.
import AWSAppSyncClient from "aws-appsync";
import appSyncConfig from './appsync_config';
// create AppSync client using the configuration JS downloaded from the AppSync dashboard
const client = new AWSAppSyncClient({
url: appSyncConfig.aws_appsync_graphqlEndpoint,
region: appSyncConfig.aws_appsync_region,
auth: {
type: appSyncConfig.aws_appsync_authenticationType,
apiKey: appSyncConfig.aws_appsync_apiKey,
}
});
Then use the Apollo provider to make your AppSync client available everywhere in the application.
const WithProvider = () => (
<ApolloProvider client={client}>
<Rehydrated render={({ rehydrated }) => (
rehydrated ? <App /> : <strong>Your custom UI component here...</strong>
)}
/>
</ApolloProvider>
);
The fetchArticles query template using graphql-tag:
import gql from 'graphql-tag'
export default gql`
query fetchArticles($offset: Int, $limit: Int) {
fetchArticles(offset: $offset, limit: $limit) {
hits {
path
title
excerpt
}
success
results
total
offset
}
}
`
The Articles component provides the main route of my application and uses the above query to render the initial article list and the pagination logic with previous/next links and using Apollo’s refetch() function.
The glamor module is unimportant, it is just used for inline css.
import React from 'react'
import { css } from 'glamor'
import { graphql } from 'react-apollo'
import FetchArticles from './queries/FetchArticles'
const pageLimit = 3;
// a query component with a graphql wrapper for fetching data
class Articles extends React.Component {
render() {
return (
<div {...css(styles.container)}>
<h1 {...css(styles.heading)}>Articles</h1>
{
this.props.offset > 0 && (
<div {...css(styles.navlink)}
onClick={() => {
this.props.refetch({
offset: this.props.offset - pageLimit,
limit: pageLimit
})
}
}>< Previous</div>
)}
{
this.props.offset + pageLimit < this.props.total && (
<div {...css(styles.navlink)}
onClick={() => {
this.props.refetch({
offset: this.props.offset + pageLimit,
limit: pageLimit
})
}
}>Next ></div>
)}
{
this.props.articles.map((r, i) => (
<article {...css(styles.article)}>
<header>
<h2 {...css(styles.title)}>
<a {...css(styles.link)} href={r.path}>{r.title}</a>
</h2>
</header>
<p>{r.excerpt}</p>
{r.res}
</article>
))
}
</div>
)
}
}
const styles = {
title: {
margin: '0px'
},
navlink: {
color: 'lightblue',
fontSize: 24
},
container: {
display: 'flex',
flexDirection: 'column',
paddingLeft: 100,
paddingRight: 100,
textAlign: 'left'
},
link: {
color: '#E10098'
}
}
export default graphql(FetchArticles, {
options: {
variables: { offset: 0, limit: pageLimit },
fetchPolicy: 'network-only'
},
props: props => ({
articles: props.data.fetchArticles ? props.data.fetchArticles.hits : [],
offset: props.data.fetchArticles ? props.data.fetchArticles.offset : 0,
total: props.data.fetchArticles ? props.data.fetchArticles.total : 0,
refetch: props.data.refetch
})
})(Articles)
Clicking an article link loads the article on a full page. For this, the following graphql-tag query template is used.
import gql from 'graphql-tag'
export default gql`
query fetchArticle($path: String!) {
fetchArticle(path: $path) {
title
body
assets
}
}
`
The full article is displayed by the following component. (Sorry, but no article markup, rich snippets, digital assets, yet.)
Article.js:
import React from 'react'
import { css } from 'glamor'
import { graphql } from 'react-apollo'
import fetchArticle from './queries/FetchArticle'
// a query component with a graphql wrapper for fetching data
class Article extends React.Component {
render() {
return (
<div {...css(styles.container)}>
<h1 {...css(styles.title)}>{this.props.title}</h1>
{
this.props.body && (
<p {...css(styles.articleBody)}>
{this.props.body}
</p>
)
}
</div>
)
}
}
const styles = {
title: {
margin: '0px'
}
}
export default graphql(fetchArticle, {
options:
props => ({
variables: { path: props.location.pathname },
fetchPolicy: 'network-only'
}),
props: props => ({
title: props.data.fetchArticle ? props.data.fetchArticle.title : "",
body: props.data.fetchArticle ? props.data.fetchArticle.body : "",
assets: props.data.fetchArticle ? props.data.fetchArticle.assets : [],
refetch: props.data.refetch
})
})(Article)
Finally, a section for those who are interested in mocking the AEM endpoints.
Mocking the AEM endpoints
- [GET] /bin/querybuilder -> LAMBDA PROXY integration
- [GET] /content/{experience+} -> MOCK integration
Here is the API mock’s resource/method structure on AWS API Gateway.
Query builder mock
The purpose of this mock is to simulate the AEM query builder for retrieving a list of articles (path, title and excerpt) from a specific path of the repository and provide parameters for pagination (total, offset, limit)
A little logic is needed in this mock in order to calculate the pagination attributes, therefore I choose AWS Lambda and node.js to build this mock.
Sling Model Exporter mock
This is a MOCK integration on the API Gateway that can be built with simple response template configuration. It returns the JSON representation of the requested page the same as how Sling Model Exporters would output it.
Here the API gateway handles all requests to /content/… and I retrieve the mock JSON response by checking the path that is received in the experience parameter.
Summary
Although this use case is far from being production ready (e.g. many quality attributes not addressed at all), I believe it successfully demonstrates the simplicity of GraphQL and how practical it is to build an easy to consume, frontend directed API. Exposing AEM content this way may be an unusual method but has several benefits as listed in the article.
From this point it is up to you to adopt / expand it.
(Cover image from https://mn.wikipedia.org/wiki/API.)
Can we try the GraphQL setup with AEM running in localhost?
No, in this setup the AEM instance must be accessible on the internet so that the AWS AppSync resolver can access it. That’s the reason I why mocked AEM content services on AWS for the blog post.
Hi, I just looked at your website and really impressed by it’s design and content. You are doing a great job by providing such data to the people. Thank you so much.